


 è una piattaforma digitale “enterprise” dedicata alla definizione, creazione, pianificazione e monitoraggio di “Data Pipelines”. Consente l’integrazione e l’orchestrazione dei flussi e sorgenti dati per supportare le esigenze della tua azienda.
è una piattaforma digitale “enterprise” dedicata alla definizione, creazione, pianificazione e monitoraggio di “Data Pipelines”. Consente l’integrazione e l’orchestrazione dei flussi e sorgenti dati per supportare le esigenze della tua azienda. 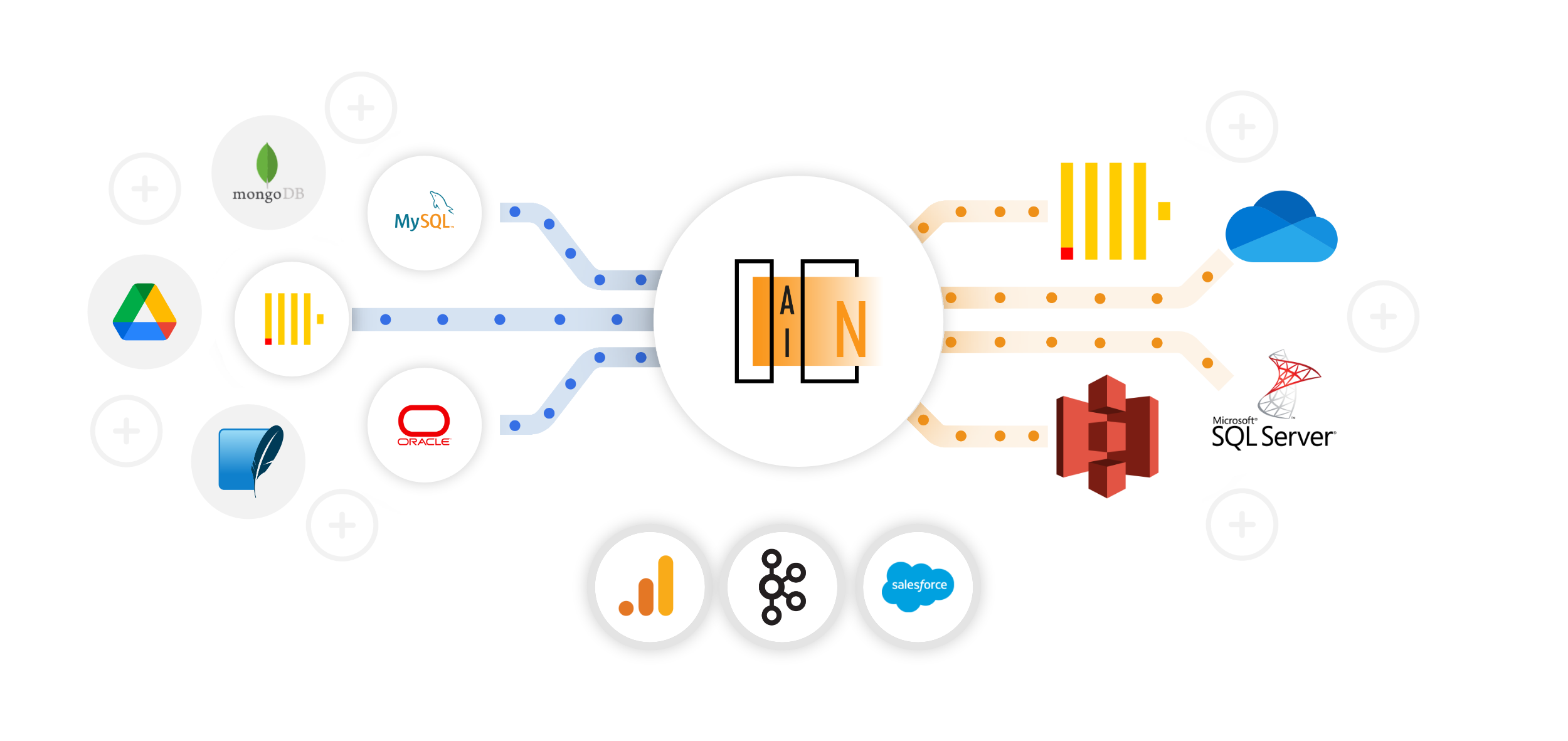
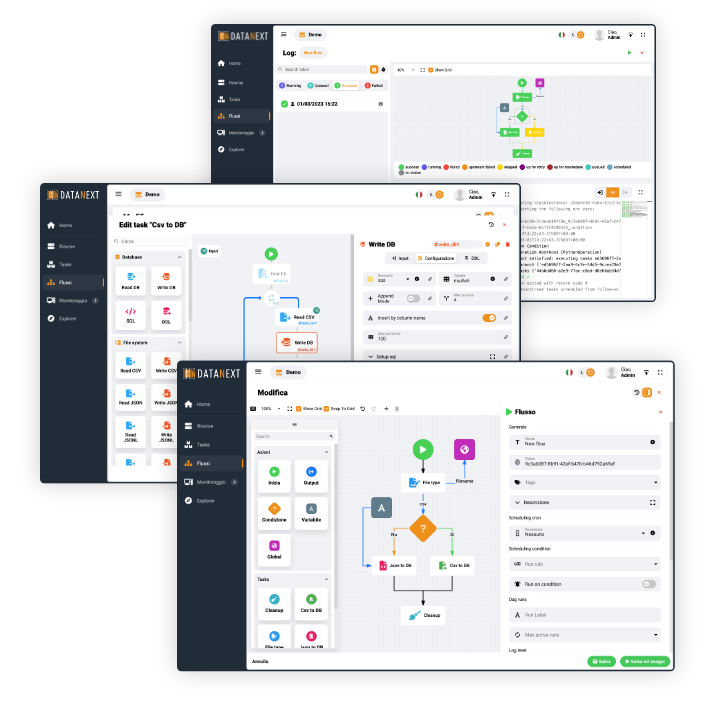 è una piattaforma digitale “enterprise” dedicata alla definizione, creazione, pianificazione e monitoraggio di “Data Pipelines”. Consente l’integrazione e l’orchestrazione dei flussi e sorgenti dati per supportare le esigenze della tua azienda.
è una piattaforma digitale “enterprise” dedicata alla definizione, creazione, pianificazione e monitoraggio di “Data Pipelines”. Consente l’integrazione e l’orchestrazione dei flussi e sorgenti dati per supportare le esigenze della tua azienda.