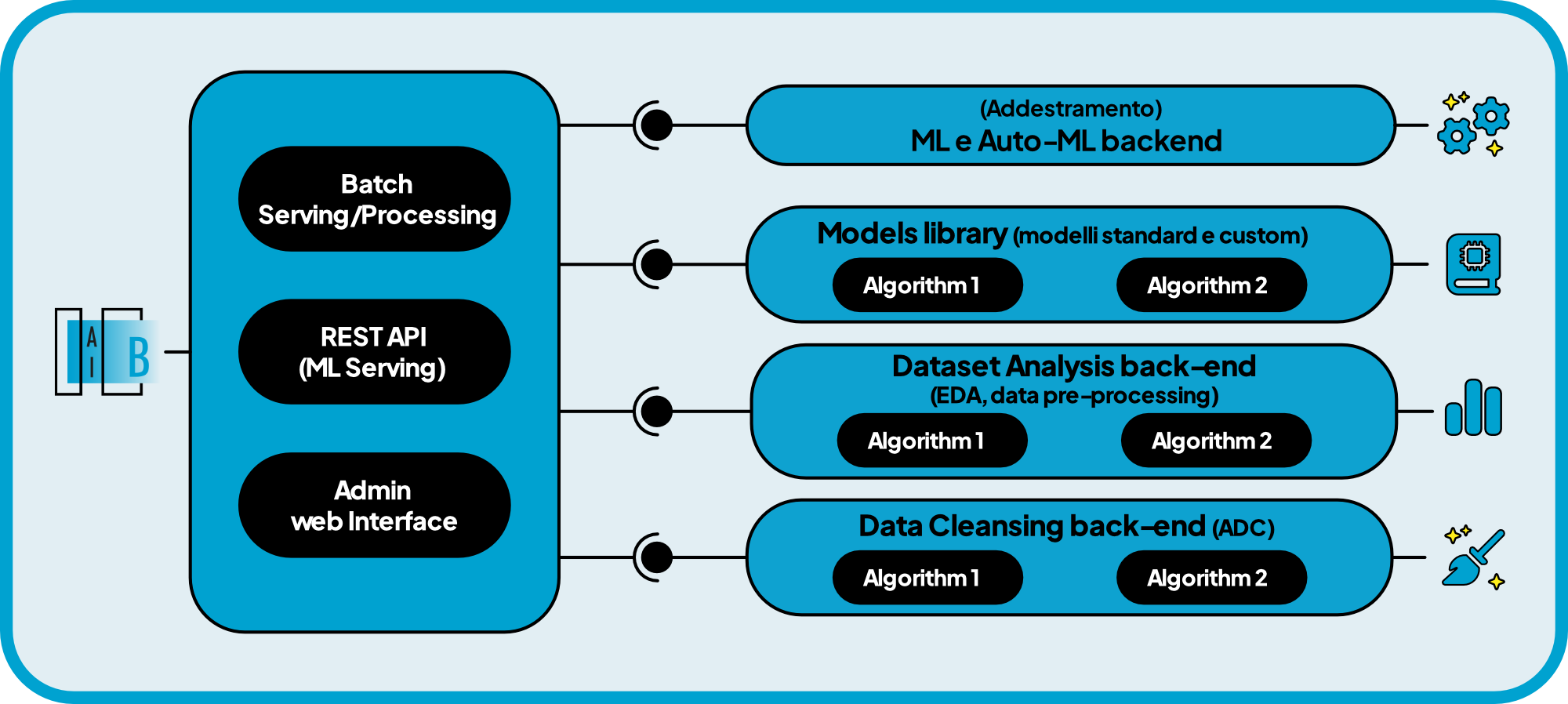
ML e Auto-ML backend
Consente di addestrare, convalidare, mettere a punto modelli AI di apprendimento automatico (Machine Learning) su dati strutturati senza scrivere codice (Low Code) o ricorrere a complesse attività di preparazione del dato.

ML Model Catalog (library)
Consente di utilizzare una vasta selezione di modelli preconfigurati, personalizzarli o caricare soluzioni su misura.

ML Trainer
Consente il controllo completo sul processo di addestramento come la scelta del framework ML preferito, la scrittura eventuale del codice Python personalizzato, l’accesso alle opzioni di ottimizzazione degli iper-parametri.

ML Serving Engine
Permette di esporre i modelli ML, tramite API, a tutte le applicazioni aziendali con un servizio scalabile di ultima generazione (multi-cloud e multi-engine) ottimizzato per i “work-load” dell’AI.